bulkRNAseq TD timing processing scripts and fig5F
File added
File added
DGE/DGE.R
0 → 120000
File added
File added
File added
This diff is collapsed.
{kind=link}
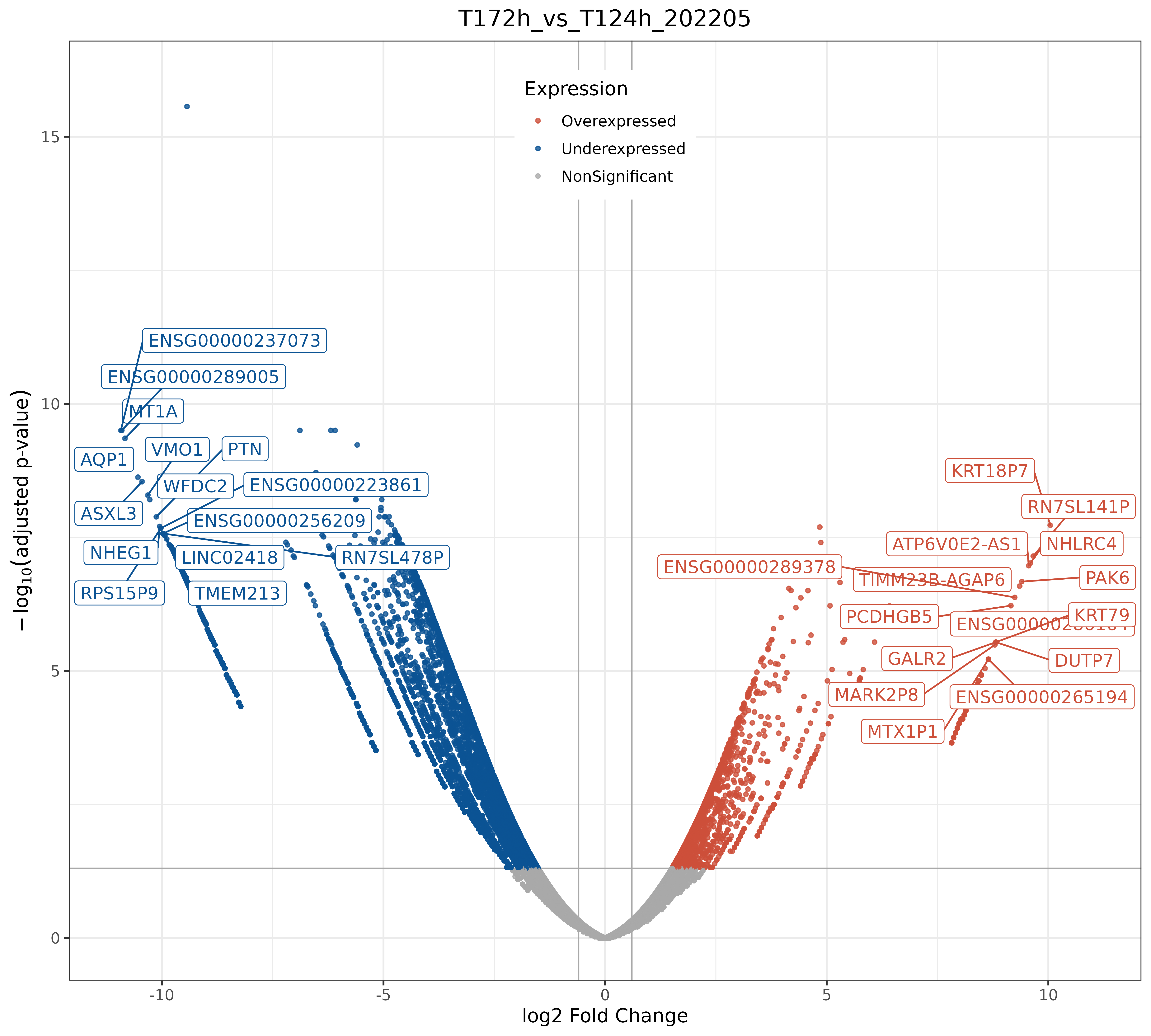
1.61 MB
File added
This diff is collapsed.
{kind=link}
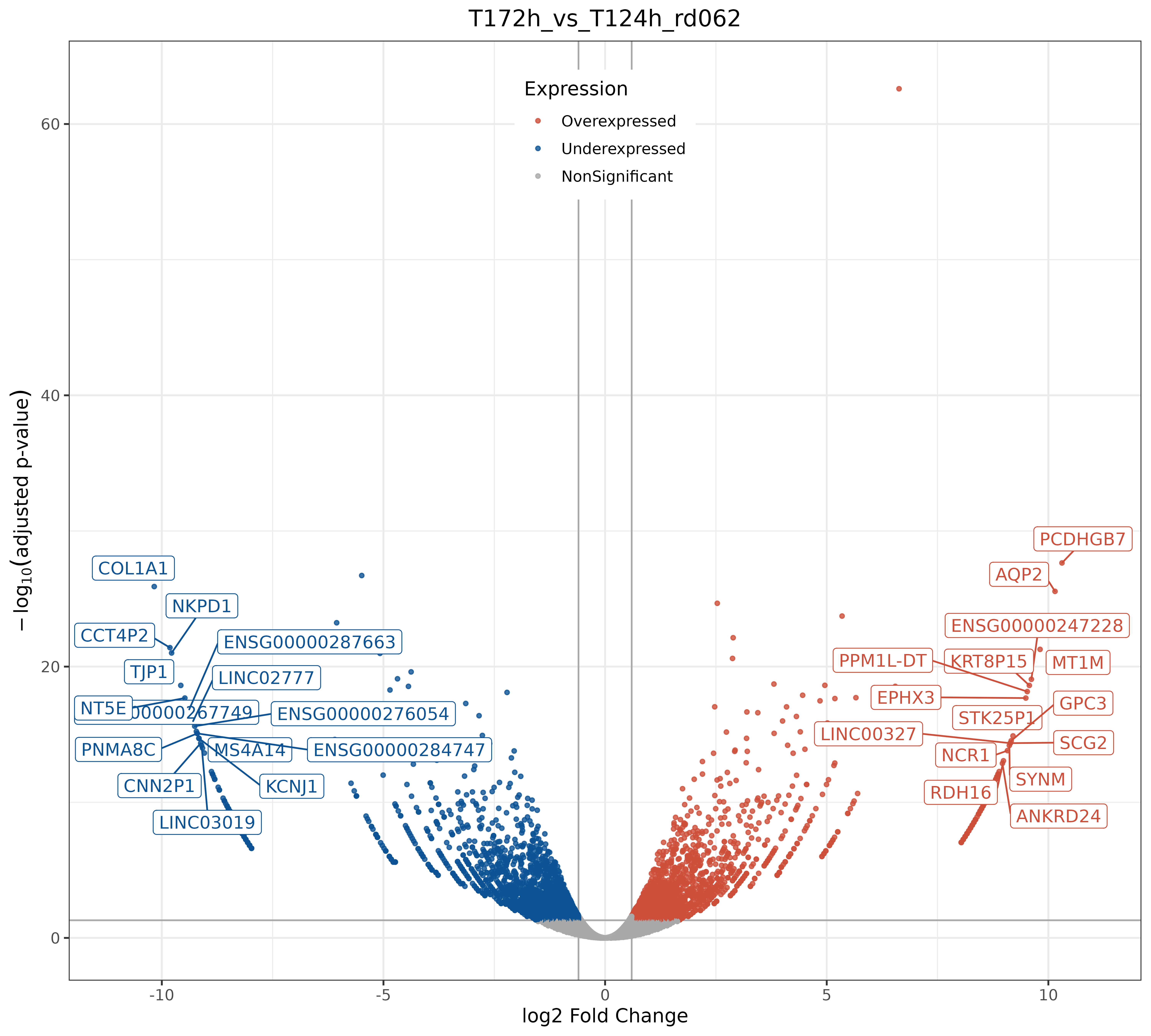
1.38 MB
File added
Fig5F_processing_and_plot.R
0 → 100644
geneList_input_vector.rds
0 → 100644
File added
sasp.gmt
0 → 100755
senescence_full.gmt
0 → 100755
senescence_signatures.gmt
0 → 100755